Blog Series
- Azure Search Overview
- Pushing Content To An Index with the .NET SDK
Azure Search is a platform-as-a-service offering. This requires code and configuration to set up and use.
Applicable corporate scenarios
- Enterprise search on many repositories of data or files that are intended to be available for a wide audience. A lightweight one-stop shop for finding any information chosen to be indexed
- Add search functionality to an existing application that does not have its own search functionality. Such as public internet company website.
- A custom search against multiple sources of log files.
Search Service
In the Azure Portal, create a new Azure Search service. The free tier should be sufficient for proof of concept purposes.

The Index
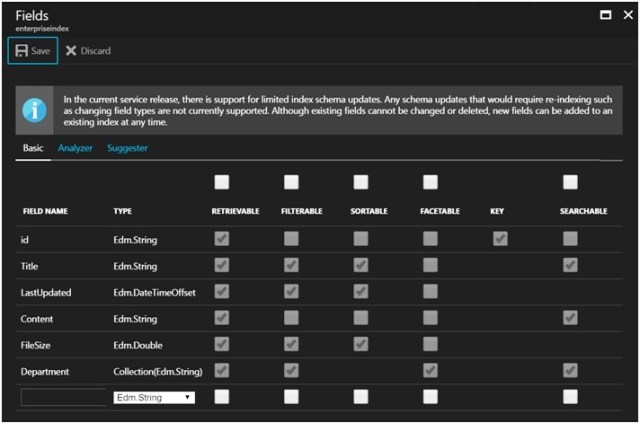
The index is the heart of any search engine where content is stored in a way that is searchable for fast and accurate retrieval. The index needs to be configured with a schema that defines custom fields by its name, type, and attribute.
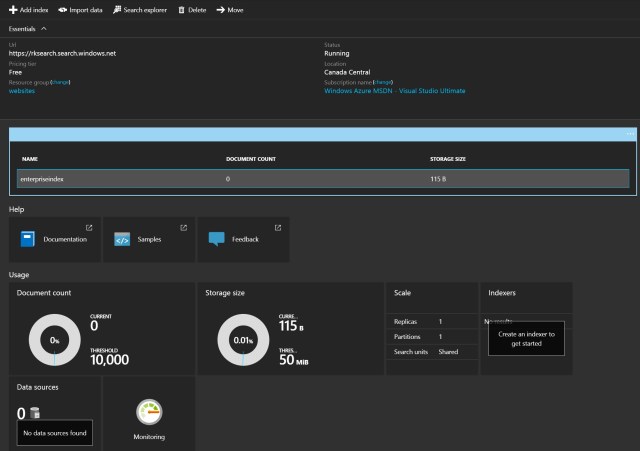
Overview blade:
Index Fields:
Field Types
Type & Description
Edm.String – Text that can optionally be tokenized for full-text search (word breaking, stemming, etc).
Collection(Edm.String) – A list of strings that can optionally be tokenized for full-text search. There is no theoretical upper limit on the number of items in a collection, but the 16 MB upper limit on payload size applies to collections.
Edm.Boolean – Contains true/false values.
Edm.Int32 – 32-bit integer values.
Edm.Int64– 64-bit integer values.
Edm.Double – Double-precision numeric data.
Edm.DateTimeOffset – Date time values represented in the OData V4 format (e.g. yyyy-MM-ddTHH:mm:ss.fffZ or yyyy-MM-ddTHH:mm:ss.fff[+/-]HH:mm).
Edm.GeographyPoint -A point representing a geographic location on the globe.
Field attributes
Attribute & Description
Key – A string that provides the unique ID of each document, used for document look up. Every index must have one key. Only one field can be the key, and its type must be set to Edm.String.
Retrievable – Specifies whether a field can be returned in a search result.
Filterable – Allows the field to be used in filter queries.
Sortable – Allows a query to sort search results using this field.
Facetable – Allows a field to be used in a faceted navigation structure for user self-directed filtering. Typically fields containing repetitive values that you can use to group multiple documents together (for example, multiple documents that fall under a single brand or service category) work best as facets.
Searchable – Marks the field as full-text searchable.
You can’t change an existing field. You can only add to the schema. If you have change existing fields, you have to delete the index, re-create with the new specifications and re-index your content. I suggest you automate this process by creating your own management app with the.NET SDK or REST API.
Refer to further guidance and sample code at Create an Azure Search index using the .NET SDK
Indexing
To populate the index from data sources, you need indexers. There are two approaches of indexing:
- Pushing to the index programmatically using the REST API or.NET SDK
- Pulling into the index with the Search Services’ indexer. No need for custom code.
| Indexing Approach | Pros | Cons |
| Push to index | More flexible Support any kind of data source You manage change tracking. |
Need to write custom code using REST API or.NET SDK. |
| Pull into index | Change tracking is mostly handled for you. No need to write custom code. |
Limited number of data sources that reside in Azure |
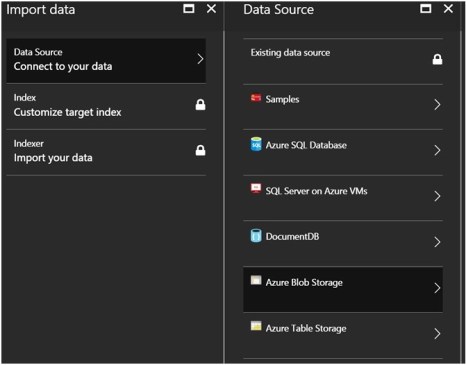
To setup a pull into the index, you can configure through the Azure Portal through the Import Data. The alternative and more comprehensive way to configure is through the REST API or.NET SDK.
Import Data
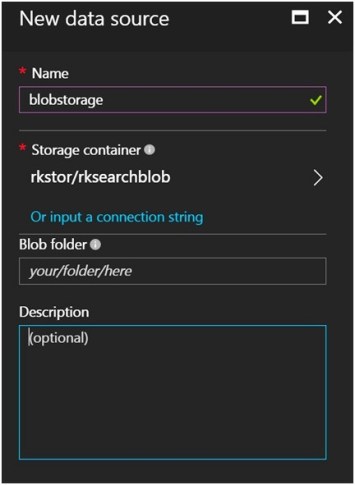
Must have already uploaded supported file types into your blob containers such as PDF and MS Office Documents.
A custom index schema will be generated for you based on the supported metadata of the specific data source. In this case, it is blob storage.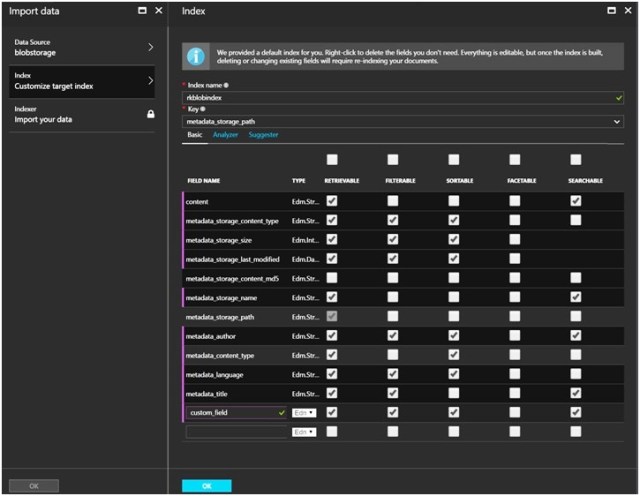
Indexer Configuration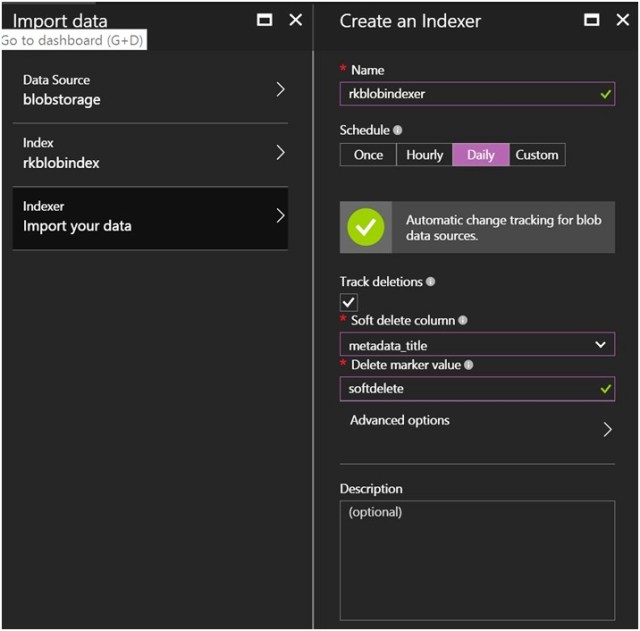
You provide the name of the indexer and the schedule of how often the indexer runs. There is automatic change tracking for new and updated documents, but deletion is handled differently. The indexer will not remove from the index unless you define a metadata field in your blob that can be marked with any value identifying it as ‘soft deleted’. In this example, we take the metadata_title field and when the document has this value as ‘softdelete’, the indexer will delete from the index. After this is known, then you can delete the document in the blob store. In my opinion, I find this process a bit complex to handle. This may need some custom application to scan through blob store and the index to see if there is any difference and delete in the blob store.
Search Explorer
Test the index with the Search Explorer by inputting your query string of search keys, filters, and other operators
Since I had uploaded some PDF and Word documents on Azure, I’ll search on “Azure”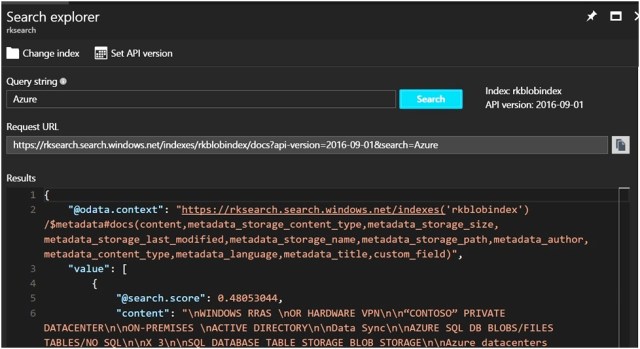
Also, scrolling further down, you can see the results of the metadata fields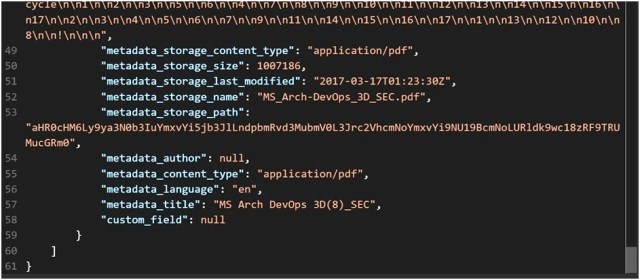
To setup a push approach to the index, you have to either use the REST API or .NET SDK.
- Add, Update or Delete Documents (Azure Search Service REST API)
- Populating the index with documents (Search .NET SDK)
You build a custom application that interfaces with your data source and use the above options to push the content to the index.
To see further details, click to my blog post – Azure Search: Pushing to an Index with the .NET SDK

Pingback: Azure Search: Pushing Content to an Index with the .NET SDK. | Roy Kim on SharePoint, Azure, BI, Office 365
Pingback: First Glance at Microsoft Search Admin Portal – Roy Kim on Azure, Office 365 and SharePoint