Blog Series
- Azure Search Overview
- Pushing Content To An Index with the .NET SDK
I hold the opinion that for a robust indexing strategy, you would likely end up writing a custom batch application between your desired data sources and your defined Azure Search index. The pull method currently only supports data sources that reside in specific Azure data stores (as of Feb 2017):
- Azure SQL Database
- SQL Server relational data on an Azure VM
- Azure DocumentDB
- Azure Blob storage, Table storage
I would assume many at this time would have desired content in websites databases and LOB applications outside of these Azure data stores.
Azure Search .NET SDK
This article Upload data to Azure Search using the .NET SDK gives great guidance and is what I used, but here’s my specific implementation approach.
To get started, first create a .NET project.
Install from NuGet

My project with the Microsoft.Azure.Search library

To start coding, define your search index by creating a model class. I created a generic index schema. I will use this to define and create a new search index in the Azure Search Service. And to hold a list of records of movies as my searchable content.
[SerializePropertyNamesAsCamelCase ]
public partial class IndexModel
{
[Key]
[IsRetrievable(true)]
public string Id { get; set; }
[IsRetrievable(true), IsSearchable, IsFilterable, IsSortable]
public string Title { get; set; }
[IsRetrievable(true), IsSearchable]
[Analyzer(AnalyzerName.AsString.EnLucene)]
public string Content { get; set; }
[IsFilterable, IsFacetable, IsSortable]
public string ContentType { get; set; }
[IsRetrievable(true)IsFilterable, IsSortable, IsSearchable]
public string Url { get; set; }
[IsRetrievable(true)IsFilterable, IsSortable]
public DateTimeOffset? LastModifiedDate { get; set; }
[IsRetrievable(true)IsFilterable, IsSortable]
public string Author { get; set; }
}
Next, I do 3 major steps in the Main method of the console app
- Create mock data, as if this data was retrieved from a data source.
- Create and index, if one not already exists, based on the index model class
- Update the index with new or updated content.
public static void Main(string[] args)
{
// Mock Data
List<IndexModel> movies = new List<IndexModel>
{
new IndexModel()
{
Id = "1000",
Title = "Star Wars",
Content = "Star Wars is an American epic space opera franchise, centered on a film series created by George Lucas. It depicts the adventures of various characters a long time ago in a galaxy far, far away",
LastModifiedDate = new DateTimeOffset(new DateTime(1977, 01, 01)),
Url = @"http://starwars.com"
},
new IndexModel()
{
Id = "1001",
Title = "Indiana Jones",
Content = @"The Indiana Jones franchise is an American media franchise based on the adventures of Dr. Henry 'Indiana' Jones, a fictional archaeologist. It began in 1981 with the film Raiders of the Lost Ark",
LastModifiedDate = new DateTimeOffset(new DateTime(1981, 01, 01)),
Url = @"http://indianajones.com"
},
new IndexModel()
{
Id = "1002",
Title = "Rocky",
Content = "Rocky Balboa (Sylvester Stallone), a small-time boxer from working-class Philadelphia, is arbitrarily chosen to take on the reigning world heavyweight champion, Apollo Creed (Carl Weathers), when the undefeated fighter's scheduled opponent is injured.",
LastModifiedDate = new DateTimeOffset(new DateTime(1976, 01, 01)),
Url = @"http://rocky.com"
}
};
AzureSearch.CreateIndexIfNotExists<IndexModel>("movies");
AzureSearch.UpdateIndex("movies", movies);
Console.WriteLine("Enter any key to exist");
Console.ReadKey();
}
In the Azure Portal, you will see the outcomes
- The ‘movies’ index has been created along with 3 documents as expected.

- I find that the document count value takes several minutes’ or more to be updated, but the indexing is immediate.
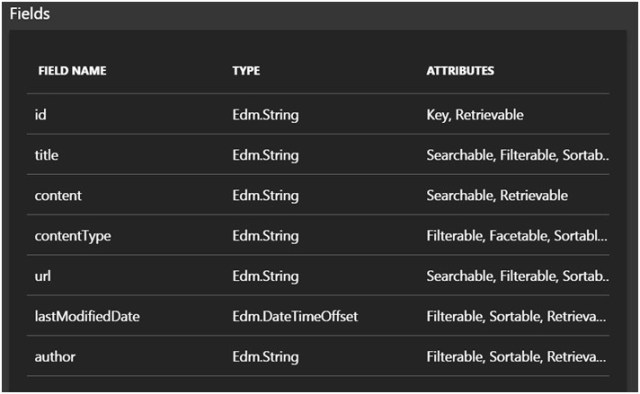
- The fields has been defined along with its type and attributes based on the index model class
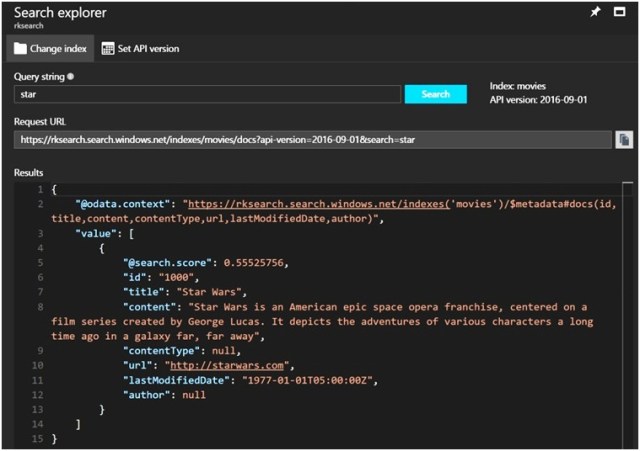
- To test the index, use the Search Explorer
For further code snippet details of the following method calls. I made this method dynamic such that you pass in the Type of the index model as T. Then the FieldBuilder.BuildForType() will build out the index schema.
AzureSearch.CreateIndexIfNotExists<IndexModel>("movies");
public static Boolean CreateIndexIfNotExists<T>(string indexName)
{
bool isIndexCreated = false;
List<string> suggesterFieldnames = new List<string>() { "title" };
var definition = new Index()
{
Name = indexName,
Fields = FieldBuilder.BuildForType<T>(),
Suggesters = new List<Suggester>() {
new Suggester() {
Name = "Suggester",
SearchMode = SuggesterSearchMode.AnalyzingInfixMatching,
SourceFields = suggesterFieldnames
}
}
};
SearchServiceClient serviceClient = CreateSearchServiceClient();
if (!serviceClient.Indexes.Exists(indexName))
{
serviceClient.Indexes.Create(definition);
isIndexCreated = true;
}
else
isIndexCreated = false;
}
AzureSearch.UpdateIndex("movies", movies);
inner method call:
private static void UploadDocuments(ISearchIndexClient indexClient, List<IndexModel> contentItems)
{
var batch = IndexBatch.MergeOrUpload(contentItems);
indexClient.Documents.Index(batch);
}
In conclusion, I generally recommend the push approach using the Azure Search .NET SDK as there are more control and flexibility. As I created a CreateIndex method, you should create a delete index method. This helps during development process as you iterate upon defining your index schema. Even in production scenarios, it can be appropriate to delete your index, re-create index with an updated schema and then re-index your content.

Pingback: First Glance at Microsoft Search Admin Portal – Roy Kim on Azure, Office 365 and SharePoint
Pingback: Azure Search Overview – Roy Kim on Azure, Office 365 and SharePoint