In my blog post Populating Data into Hive Tables in HDInsight, I have demonstrated populating an internal and an external hive table in HDInsight. The primary storage is configured with Azure Data Lake Store.
To see the differences, I will demonstrate dropping both types of tables and observe the effects. This for the beginner audience.
To recap the linked post, the internal hive table has its own copy of the csv file of crimes data. The external hive table crimes_ext has a pointer to the folder containing its data.The hive tables to drop as seen through Visual Studio
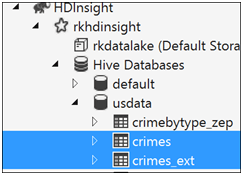
In Azure Data Lake Store, the tables are under \clusters\rkhdinsight\hive\warehouse\usdata.db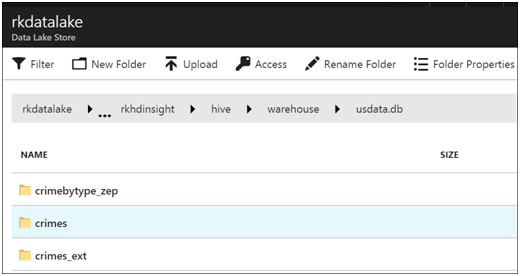
Clicking into the crimes folder, we see the data file.

Clicking into the crimes_ext folder, there is no data file.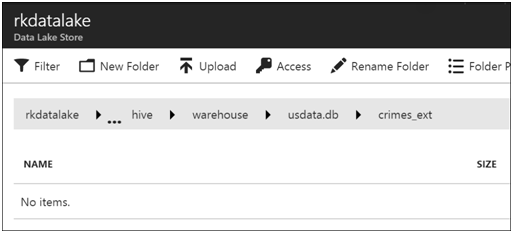
Since crimes_ext is an external table, its data is configured to be under \datsets\Crimes
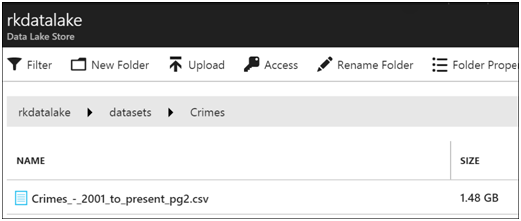
Out of curiosity, I look in the external hive metastore in an Azure SQL Database. There is a table TBLS with a list of tables and its type. The hive metastore contains the metdata of the hive table, but no data. Dropping the tables
Dropping the tables
Use usdata; DROPTABLE crimes_ext; DROPTABLE crimes;
In Server Explorer, after refreshing the usdata database, they are gone.
In ADLS, the crimes folder is removed which was the internal table. However, the crimes_ext folder still exists for reasons I am not aware.
To check the data of the external table, we see its data file not removed, which is expected by design.

Going back to the hive metastore, we see the two tables removed.
Side note: The hive view crimesgroupbytype_view queries the dropped internal hive table and if you run the view, you get an error stating the dependency of the missing hive table.
The concepts of dropping internal and external tables are easy to understand, but I just want to show the underlying effects in Azure Data Lake Store and the hive metastore DB for the beginner.
