Objective: Create an internal and an external hive tables in HDInsight. Based on the schema of a CSV file on US city crime. https://catalog.data.gov/dataset/crimes-2001-to-present-398a4
Building Hive tables establishes a schema on the flat files that I have stored in Azure Data Lake Store. This will allow me to do SQL like queries with HiveQL on that data. In other words, I have a data warehouse in Hive. and can be the basis of building big data analytical applications.
For an overview of Hive, read https://hortonworks.com/apache/hive/
- Open Visual Studio with Data Lake Tools plugin.
- Create New Project
- In Server Explorer, ensure you are connected to an HDInsight cluster
- In Solution Explorer, create a new HiveQL script to create tables
- Create Database
CREATE DATABASE IF NOT EXISTS USData; use USData;
- Create internal table
CREATE TABLE IF NOT EXISTS Crimes ( ID INT , CaseNumber STRING, CrimeDate DATETIME, Block STRING, IUCR INT, PrimaryType STRING, Description STRING, LocationDescription STRING, Arrest BOOLEAN, Domestic BOOLEAN, Beat INT, District INT, Ward INT, CommunityArea INT, FBICode INT, XCoord INT, YCoord INT, Year INT, UpdatedOn DATETIME, Latitude FLOAT, Longitude FLOAT, CrimeLocation STRING ) FIELDS TERMINATED by ',' stored as textfile tblproperties ("skip.header.line.count"="1"); - Create external table
CREATE EXTERNAL TABLE IF NOT EXISTS Crimes_EXT ( ID INT, CaseNumber STRING, CrimeDate DATE, Block STRING, IUCR INT, PrimaryType STRING, Description STRING, LocationDescription STRING, Arrest BOOLEAN, Domestic BOOLEAN, Beat INT, District INT, Ward INT, CommunityArea INT, FBICode INT, XCoord INT, YCoord INT, Year INT, UpdatedOn DATE, Latitude FLOAT, Longitude FLOAT, CrimeLocation STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED by ',' stored as textfile tblproperties ("skip.header.line.count"="1"); - Submitting one of the scripts
- As a result, crimes and crimes_ext tables are created.
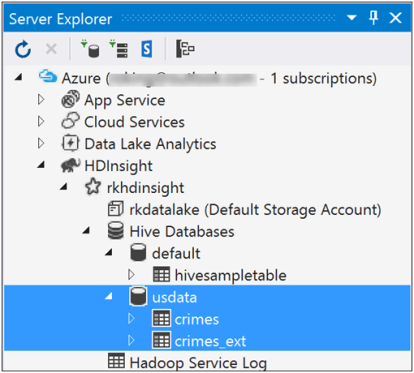
- Expanding the tables, shows the fields Internal/managed vs External Hive Tables

For further details to create tables, read https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-ManagedandExternalTables
To populate these hive tables with data, read further to my article Populating Data into Hive Tables in HDInsight.

Pingback: Populating Data into Hive Tables in HDInsight – Roy Kim on SharePoint, Azure, BI, Office 365
Small corrections. DATETIME is not supported, use timestamp.
I made the table properties more specific as well
CREATE TABLE IF NOT EXISTS Crimes
(
ID INT ,
CaseNumber STRING,
CrimeDate timestamp,
Block STRING,
IUCR INT,
PrimaryType STRING,
Description STRING,
LocationDescription STRING,
Arrest BOOLEAN,
Domestic BOOLEAN,
Beat INT,
District INT,
Ward INT,
CommunityArea INT,
FBICode INT,
XCoord INT,
YCoord INT,
Year INT,
UpdatedOn timestamp,
Latitude FLOAT,
Longitude FLOAT,
CrimeLocation STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED by ‘,’
LINES TERMINATED by ‘\n’
stored as textfile
tblproperties (“skip.header.line.count”=”1”);
Further enhancements as I was looking at the data further. The last field is surrounded with double quotes, so you need to use a SerDe to properly handle the data. Further, I changed the dates to string since they werent getting parsed properly and returning null
drop table crimes_ext;
CREATE EXTERNAL TABLE IF NOT EXISTS Crimes_EXT
(
ID INT,
CaseNumber STRING,
CrimeDate STRING,
Block STRING,
IUCR INT,
PrimaryType STRING,
Description STRING,
LocationDescription STRING,
Arrest BOOLEAN,
Domestic BOOLEAN,
Beat INT,
District INT,
Ward INT,
CommunityArea INT,
FBICode INT,
XCoord INT,
YCoord INT,
Year INT,
UpdatedOn STRING,
Latitude FLOAT,
Longitude FLOAT,
CrimeLocation STRING
)
ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.OpenCSVSerde’
WITH SERDEPROPERTIES (
“separatorChar” = “,”,
“quoteChar”=”\””,
“escapeChar”=”\\”
)
stored as textfile
LOCATION ‘adl://azueus2devadlsdatalake.azuredatalakestore.net/users/patrick.picard/crime_dataset/’
tblproperties (“skip.header.line.count”=”1”);