The Spark cluster is one of the several cluster types that is offered through HDInsight platform-as-a-service. The unique capabilities of the Spark cluster are the in-memory processing that supports overall performance benefit over Hadoop cluster type. As a result, build big data analytics applications.
For further overview read https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-apache-spark-overview
I will walk through and comment on a series of steps to create a spark cluster with Azure Data Lake Store as the primary storage as opposed to Azure Blob Store. For a comparison read https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-comparison-with-blob-storage
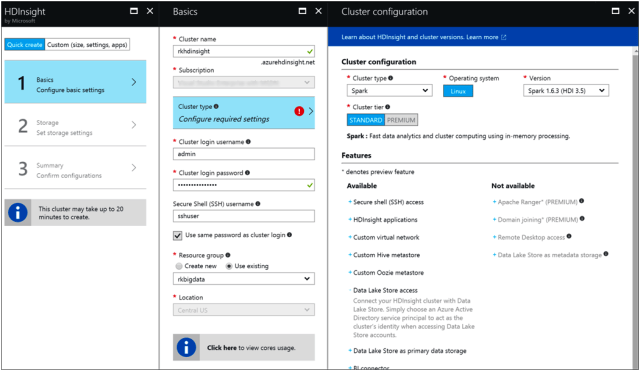
- In the Azure Portal, Create HDInsight
Fill the obvious and standard inputs.
For cluster configuration, select This version supports Data Lake store as primary data storage.
- For primary storage type, select Data Lake Store
In order for the data lake store to allow the HDInsight cluster access, we must create a service principal and Azure AD application in Azure Active Directory. This wizard helps do that. Create a certificate along with its password.
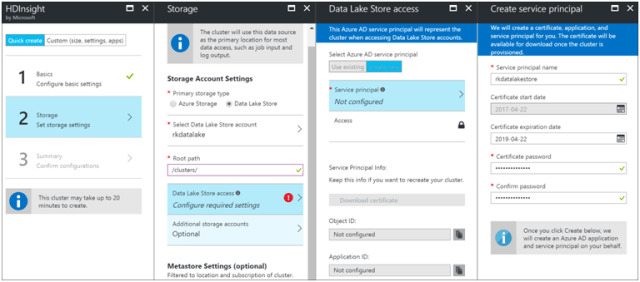
- Select the Azure Data Lake Store that was already created and grant the permissions.

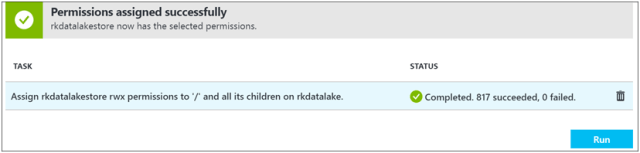
- Click Run to assign permissions to all the files and folders.
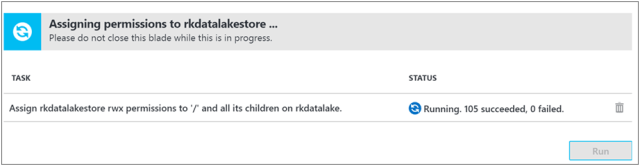
- Confirm success.
- Download the certificate and take note of the password in the future to re-provision the cluster and point to the same Data Lake Store.

- I chose to leverage an existing SQL database for Hive Metastore. This is so that definitions created for Hive databases and tables are preserved when deleting the cluster.
 Prerequisite to Step 7:
Prerequisite to Step 7:
Before starting to create the Spark Cluster, must create a blank SQL database for each Hive and Oozie metastore. This is so that the SQL databases display in the drop down selection in the previous step.
- Through this blade, you can choose the number of worker nodes and the VM size. To save on costs I chose 2 nodes as opposed to the default 4. The head nodes are always 2 and used for failover and running some services. The number of nodes cannot be changed. Note that the costs can easily be expensive as you are charged for even idle time. So I strongly consider scripting scheduled provisioning and deleting of the cluster when needed. Especially for dev environments.

- Confirm configuration

Script actions option
Allow for customizations onto the cluster such as adding additional components or configuration changes. For details read https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-customize-cluster-linuxVirtual Network optionAllow connecting to other VMs and resources made available within or the appointed virtual network. Also added network security layer. For details read https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-extend-hadoop-virtual-network - Upon completed provisioning, we see the Overview blade.

- Click on Dashboard along the top to open the Ambari web management site for administrators

- Go to the Hive View or URL looking like https://rkhdinsight.azurehdinsight.net/#/main/views/HIVE/1.5.0/AUTO_HIVE_INSTANCE to manage Hive databases and the data. This is analogous to SQL management studio.

- For Zeppelin notebooks to do interactive data analysis and queries, go to URL https://rkhdinsight.azurehdinsight.net/zeppelin

I feel the Spark cluster in HDInsight has many capabilities and advantages that I am still learning. It is a compelling option for building big data applications.
