Blog Series:
- Creating Azure Data Lake
- PowerShell and Options to upload data to Azure Data Lake Store
- Using Azure Data Lake Store .NET SDK to Upload Files
- Creating Azure Data Analytics
- Azure Data Lake Analytics: Database and Tables
- Azure Data Lake Analytics: Populating & Querying Tables
- Azure Data Lake Analytics: How To Extract JSON Files
- Azure Data Lake Analytics: U-SQL C# Programmability
- Azure Data Lake Analytics: Job Execution Time and Cost
Upon creating a table with a defined set of columns, let’s go through a basic example of populating it from a CSV file stored in Azure Data Lake.
The .csv file as the sample data to be imported into the table. I am using Data Lake Explorer in visual studio. The relative file path is \MyData\FL_insurance_sample.csv. This sample data file I got from a public website.

U-SQL application:
// Use insurance database;
USE Insurance;
// Extract from file
@csvData =
EXTRACT policyID int,
statecode string,
county string,
eq_site_limit float,
hu_site_limit float,
fl_site_limit float,
fr_site_limit float,
tiv_2011 float,
tiv_2012 float,
eq_site_deductible float,
hu_site_deductible float,
fl_site_deductible float,
fr_site_deductible float,
point_latitude float,
point_longitude float,
line string,
construction string,
point_granularity int?
FROM "/MyData/FL_insurance_sample.csv"
USING Extractors.Csv(skipFirstNRows:1);
//Insert it into a previously created table
INSERT INTO Policies
SELECT *
FROM @csvData;
Since the data file was in CSV format, I would use the Extractors.csv. Other extractors are TSV and Text file. Since the data file had a header row of column names as its first row, I had to indicate to skip the first row by stating skipFristNrows: 1. Otherwise, the script submission would result in an error because the header columns wouldn’t work with the field data types defined. There are other arguments to specify to offer more configurability and flexibility.
Submit Job
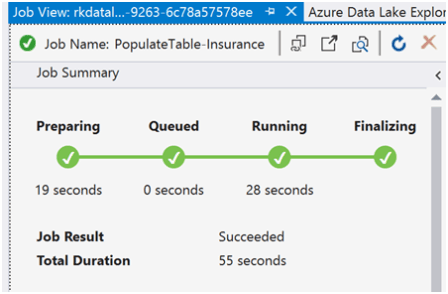
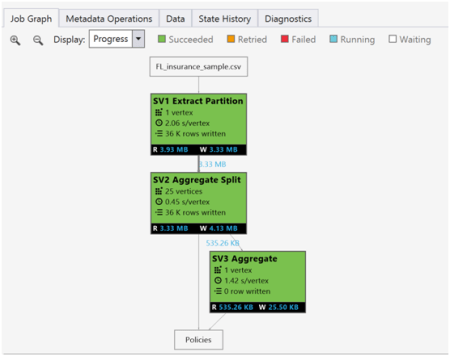
To query and see the results, they must be stored into an output file in the Azure Data Lake Store. Unfortunately, I don’t see a way to see them on a console like you do in SQL Management Studio.
// Use insurance database; USE Insurance; @queryPolicy = SELECT * FROM Policies WHERE county == "NASSAU COUNTY"; // output query into a file OUTPUT @queryPolicy TO "/MyData/queryresults/policies-by-nassaucounty.csv" USING Outputters.Csv();
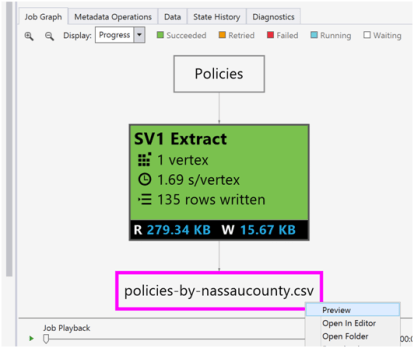
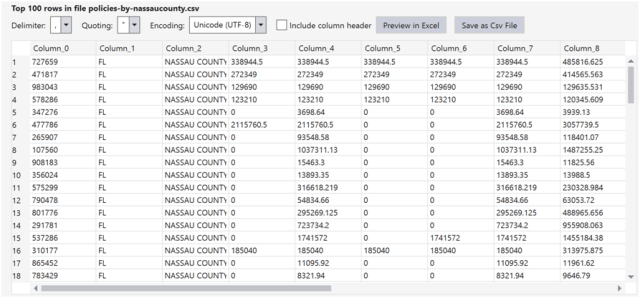
You can preview the file in Visual Studio
@queryView = SELECT * FROM PoliciesByCounty;
// output query into a file
OUTPUT @queryView
TO "/MyData/queryresults/view-by-county.csv"
USING Outputters.Csv();
Note the View definition is:
CREATE VIEW IF NOT EXISTS Insurance.dbo.PoliciesByCounty AS
SELECT COUNT(policyID) AS NumOfPolicies, county
FROM Insurance.dbo.Policies
GROUP BY county;
The preview of the output file:
I just went through some basic scenarios for populating and querying a table and view in ADLA.
References:
Tutorial: Get started with Azure Data Lake Analytics U-SQL language
U-SQL Views

Pingback: Azure Data Lake Analytics: How To Extract JSON Files – Roy Kim on SharePoint, Azure, BI, Office 365
Pingback: Azure Data Lake Analytics: Database and Tables – Roy Kim on SharePoint, Azure, BI, Office 365