Blog Series:
- Creating Azure Data Lake
- PowerShell and Options to upload data to Azure Data Lake Store
- Using Azure Data Lake Store .NET SDK to Upload Files
- Creating Azure Data Analytics
- Azure Data Lake Analytics: Database and Tables
- Azure Data Lake Analytics: Populating & Querying Tables
- Azure Data Lake Analytics: How To Extract JSON Files
- Azure Data Lake Analytics: U-SQL C# Programmability
- Azure Data Lake Analytics: Job Execution Time and Cost
Upon creating your Azure Data Lake Analytics service, you are ready to create database and tables. This is to define a schema and structure to your data. Your data may be in an semi-structured format. For the development tooling, you need to install Azure Data Lake Tools for Visual Studio as a plugin-in to Visual Studio.
This provides the ability to create U-SQL projects and functionality for development.

The catalog of Azure Data Lake Analytics:
|
Visual Studio – Sever Explorer Pane |
Azure Portal – Azure Data Lake Analytics |
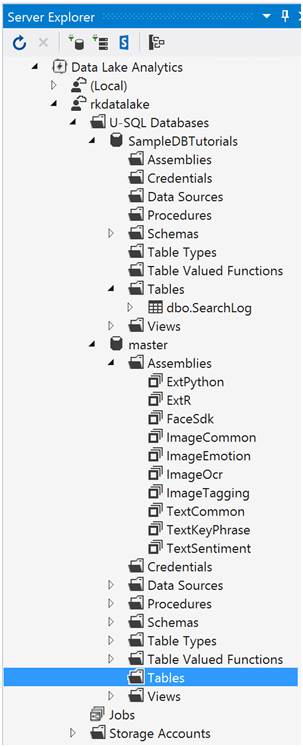
When creating tables, you have the option to create database into master database. This has assemblies that you can be leveraged in your scripts such as Cognitive Services to do key phrase extraction in text.
To create a new database and table, create a new .usql file into your U-SQL project.
//Create Database
CREATE DATABASE IF NOT EXISTS Insurance;
//Create Table
CREATE TABLE IF NOT EXISTS Insurance.dbo.Policies
(
//Define schema of table
policyID int,
statecode string,
county string,
eq_site_limit float,
hu_site_limit float,
fl_site_limit float,
fr_site_limit float,
tiv_2011 float,
tiv_2012 float,
eq_site_deductible float,
hu_site_deductible float,
fl_site_deductible float,
fr_site_deductible float,
point_latitude float,
point_longitude float,
line string,
construction string,
point_granularity int?,
INDEX idx1 //Name of index
CLUSTERED (county ASC) //Column to cluster by
DISTRIBUTED BY HASH (county) //Column distribute by
);
// CREATE VIEW based on the Policies table
CREATE VIEW IF NOT EXISTS Insurance.dbo.PoliciesByCounty AS
SELECT COUNT(policyID) AS NumOfPolicies
FROM Insurance.dbo.Policies
GROUP BY county;
- Create a database that is a container for tables, views, assemblies, schemas, table valued functions, etc..
- Create a table with a set fields with data types. The data types are C#-like in such that you can define nullable types just as I did with point_granularity as int?.
- Create an index for this table based for how rows are physically stored to one another and distribute by hash. The purpose is for efficient querying and processing.
Click Submit to submit the script as a job
![]()

In the Server Explorer pane, you will see the resulting outcome.

In the following article Azure Data Lake Analytics: Populating & Querying Tables, we will explore how to populate and query the table from a flat file from Azure Data Lake Store.

Nice blog thanks for possting