The Azure Kubernetes Service (AKS) AI toolchain operator (KAITO) provides pre-configured deployments of language models to streamline its installation by automating GPU node provisioning and inference setup. Inference is the runtime process of the model to generate outputs (text, code, embeddings, etc.) from input prompts.
https://github.com/kaito-project/kaito/tree/official/v0.5.1/examples/inference
Opening any of these inference workspace CRD yaml files, are two configuration parameters I inquire
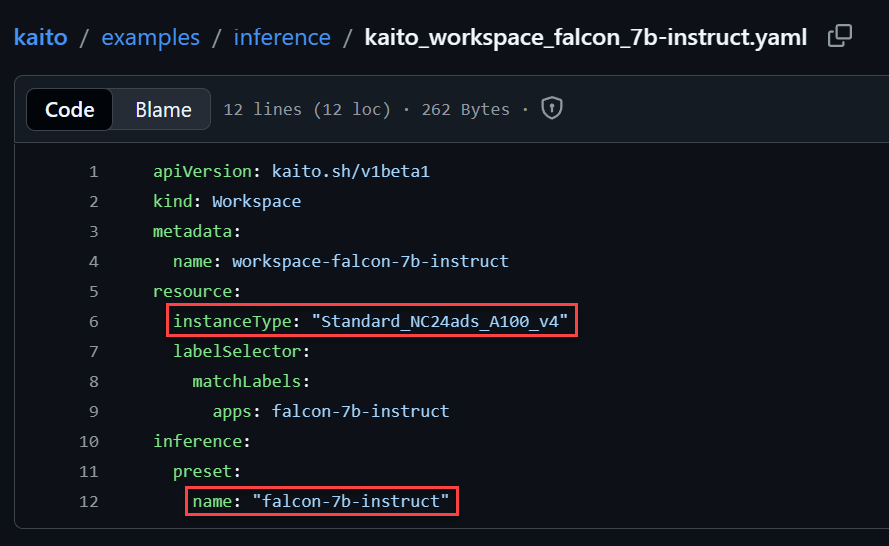
As I browse through these specific language model preset configuration examples, I ask myself
- What are these models suitable for?
- For each VM SKU instance type what is its capacities and general cost.
Supported Preset Model Families
The following taken from the inference yaml file examples.
DeepSeek
| Language model | Purpose / benefit / advantage | Best used for (scenarios) | instanceType |
| deepseek-r1-0528 | Strong multi-step reasoning | Complex planning, math/logic-heavy prompts | Standard_NC80adis_H100_v5 |
| deepseek-r1-distill-llama-8b | Cheaper/faster “reasoning-ish” behavior | Reasoning workloads with tighter latency/cost | Standard_NC24ads_A100_v4 |
| deepseek-r1-distill-qwen-14b | Distilled reasoning w/ more capacity | Mid-budget reasoning + analysis-heavy chat | Standard_NC24ads_A100_v4 |
| deepseek-v3-0324 | Strong general instruction/chat | General assistant, summarization, Q&A | Standard_NC80adis_H100_v5 |
Llama
| Language model | Best used for (scenarios) | instanceType |
| llama-3.1-8b-instruct | Default assistant, extraction, summarization | Standard_NC24ads_A100_v4 Standard_NC96ads_A100_v4 |
| llama-3.3-70b-instruct | Higher-quality responses, harder prompts | Standard_NC48ads_A100_v4 |
Falcon
| Language model | Best used for (scenarios) | instanceType |
| falcon-7b | Simple chat/completion; compatibility | Standard_NC24ads_A100_v4 |
| falcon-7b-instruct | Basic assistant tasks | Standard_NC12s_v3 |
| falcon-40b | Higher-quality completion prompts | Standard_NC96ads_A100_v4 |
| falcon-40b-instruct | Mid-tier assistant tasks | Standard_NC12s_v3 |
Mistral
| Language model | Best used for (scenarios) | instanceType |
| mistral-7b | Completion-style prompts, experimentation | Standard_NC24ads_A100_v4 |
| mistral-7b-instruct | Cost-effective chat + structured output | Standard_NC24ads_A100_v4 |
| mistral-large-3-675b-instruct | Max quality (high cost/latency) | Standard_NC80adis_H100_v5 |
| ministral-3-3b-instruct | Low-latency, high-QPS assistants | Standard_NV36ads_A10_v5 |
| ministral-3-8b-instruct | Better quality than 3B at modest cost | Standard_NC24ads_A100_v4 |
| ministral-3-14b-instruct | Stronger reasoning/writing than 8B | Standard_NC24ads_A100_v4 |
Phi
| Language model | Best used for (scenarios) | instanceType |
| phi-3-mini-4k-instruct | Quick Q&A, classification, short chat | Standard_NC4as_T4_v3 |
| phi-3-mini-128k-instruct | Long doc Q&A/summarization at low cost | Standard_NC6s_v3 Standard_NC24ads_A100_v4 |
| phi-3-medium-4k-instruct | Better quality than mini on typical prompts | Standard_NC8as_T4_v3 |
| phi-3-medium-128k-instruct | Long-context reasoning/summarization | Standard_NC24ads_A100_v4 |
| phi-3.5-mini-instruct | General low-cost assistant workloads | Standard_NC24ads_A100_v4 |
| phi-4 | Higher quality assistant than Phi-3.x | Standard_NC24ads_A100_v4 |
| phi-4-mini-instruct | Tool calling, function calling, fast chat | Standard_NC24ads_A100_v4 |
Qwen
| Language model | Best used for (scenarios) | instanceType |
| qwen2.5-coder-7b-instruct | Code gen, refactors, tests, code Q&A | Standard_NC24ads_A100_v4 |
| qwen2.5-coder-32b-instruct | Harder coding tasks, bigger refactors | Standard_NC24ads_A100_v4 |
For the InstanceType VM Skus, I find it difficult to understand what they mean and they cost. So here’s a basic breakdown that I find is sufficient.
| Component | Example Value | Description |
| Family | N | The primary workload category (e.g., N for GPU/Specialized). |
| Sub-family | C | Specialized differentiation within a family (e.g., C for Compute-intensive GPU). |
| # of vCPUs | 24 | The number of virtual CPU cores allocated to the VM. |
| Additive Features | ads | Lowercase letters denoting specific hardware traits. a (AMD-based): The processor is an AMD EPYC instead of the default Intel. d (Local Disk): The VM includes a local, non-persistent temporary SSD (Temp Disk). s (Premium Storage) |
| Accelerator Type | A100 | The specific hardware accelerator. See table below. |
| Version | v4 | The generation of the underlying hardware (e.g., v4, v5). |
To drill down the accelerator types:
| GPU | Architecture | Tier | Primary Usage |
| H100 | Hopper | Cutting-edge | Frontier AI training |
| A100 | Ampere | Enterprise flagship | Training + fine-tuning |
| A10 / A10G | Ampere | Mid-tier | Inference + moderate training |
| T4 | Turing | Entry-level | Inference |
| V100 | Volta | Legacy high-end | Older training workloads |
For testing purposes and to keep costs down, I first test preset inference models using older GPUs. This helps to understand deployment and build apps against the inference endpoint. Then move on to testing more costly and capable inference models. You can try testing an present config with a newer architecture, and then change the instance type to a smaller capacity or older SKU, but it is trial and error. A handful of times the GPU driver that comes loaded with the GPU is not compatible with the language model.
| GPU | Architecture | Tier | Primary Usage |
| H100 | Hopper | Cutting-edge | Frontier AI training |
| A100 | Ampere | Enterprise flagship | Training + fine-tuning |
| A10 / A10G | Ampere | Mid-tier | Inference + moderate training |
| T4 | Turing | Entry-level | Inference |
| V100 | Volta | Legacy high-end | Older training workloads |
Finally, here is a rough estimate of a cost breakdown. The take away are relative pricing to judge your options.
| VM SKU | GPU Type | Linux Monthly Cost (USD) | Use Case | NVIDIA Family |
| Standard_NC6s_v3 | 1x V100 | $2,044.00 | Phi-3.5 Vision / Llama-8B | Volta |
| Standard_NC24ads_A100_v4 | 1x A100 | $2,737.50 | Llama-3.2-11B Vision | Ampere |
| Standard_NC48ads_A100_v4 | 2x A100 | $5,475.00 | Llama-3.3-70B (Single Node) | Ampere |
| Standard_ND96asr_v4 | 8x A100 | $21,535.00 | Llama-3.3-70B Multi-node Cluster | Ampere |
| Standard_ND96ov_v5 | 8x H100 | $82,125.00 | Frontier Model Training / Large Clusters | Hopper |
Final Thoughts
I hope I am able to provide some direction. I want to narrow down a focus on how to think through the options. It’s important to consider how LLMs and VM SKUs relate to one another. I tested a handful of models and scenarios over the past few months. I wanted to seek more clarity. I hope this helps.
